协程系统优化
libcopp很早就实现完成了v2版本,现在迁移进atsf4g-co/tree/sample_solution以后也把v2分支正式并入了主干。原来的版本切出到v1分支并且停止维护了。
libcopp v2内存布局
开发libcopp v2版本的最大目的是优化allocator的接口和内存碎片。
原来的allocator虽然是可定制的,但是是内置的。每次创建一个allocator对象,不同allocator之间共享数据只能通过全局数据或者TLS数据。现在则可以传入allocator了。这也是为后续的共享栈池做准备。
其次就是优化结构布局以优化内存碎片问题。在v1版本里,一个很重要的设计要点是各项组件可拆卸,就是说一些设计模式层面的东西比如协程任务、任务管理、等待和依赖关系等是可选的。同时栈分配器也可以是多种选择,采用系统地址映射加保护帧、采用malloc或者自定义分配器。为了各项组件尽可能解耦和易于组合,模块间较少采用组合关系,较多采用了引用关系,原来的协程任务结构大致上是这样的。
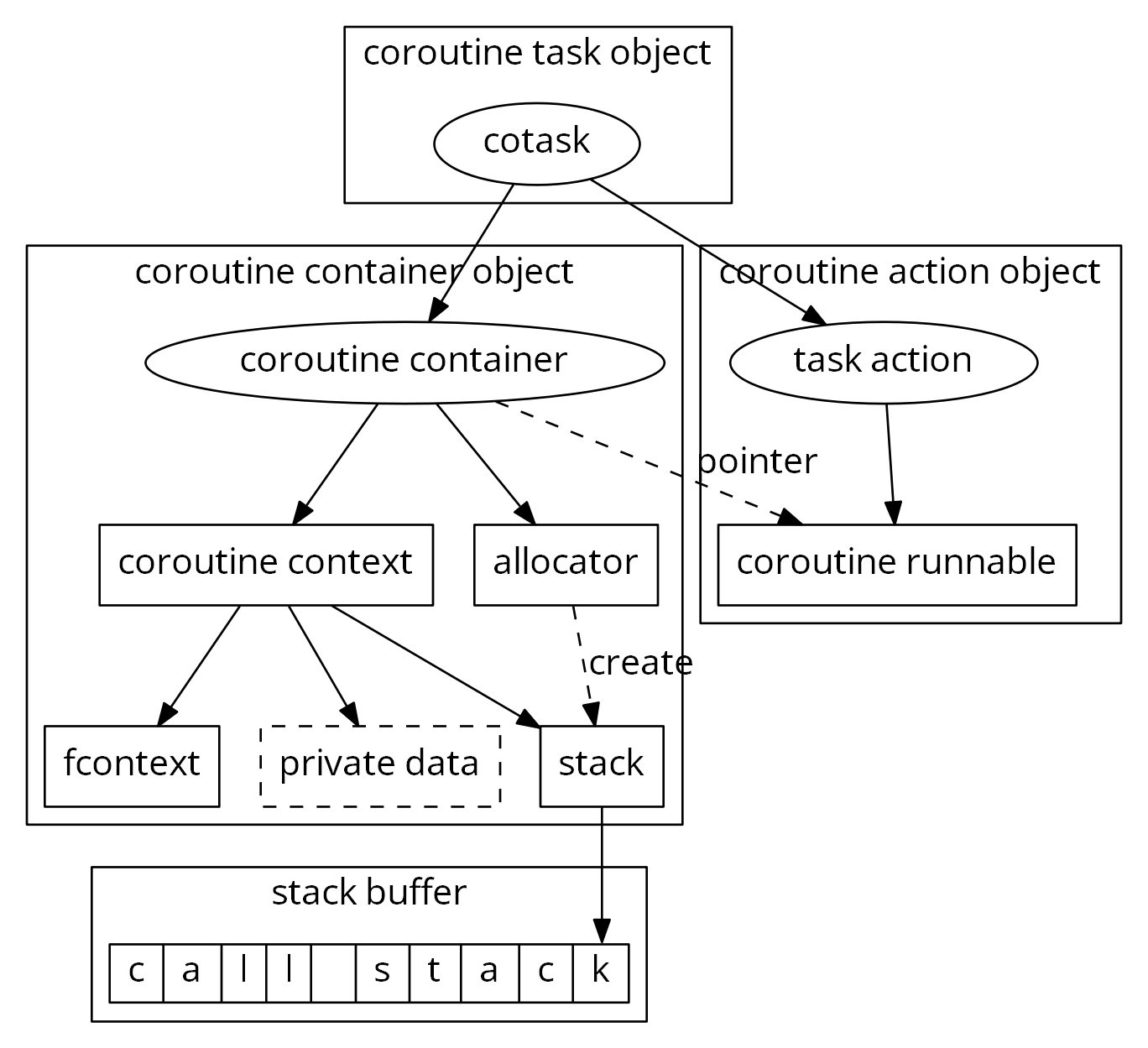
可以看得出来一个协程运行的时候对象数量很多。这样的话碎片也很多,虽然现代化的malloc实现能大幅缓解碎片问题,但是终归是有一些开销。上面图里是一个比较完整的结构关系,实际使用中有些组件如果不需要是可以移除掉的,比如 cotask 相关的部分。
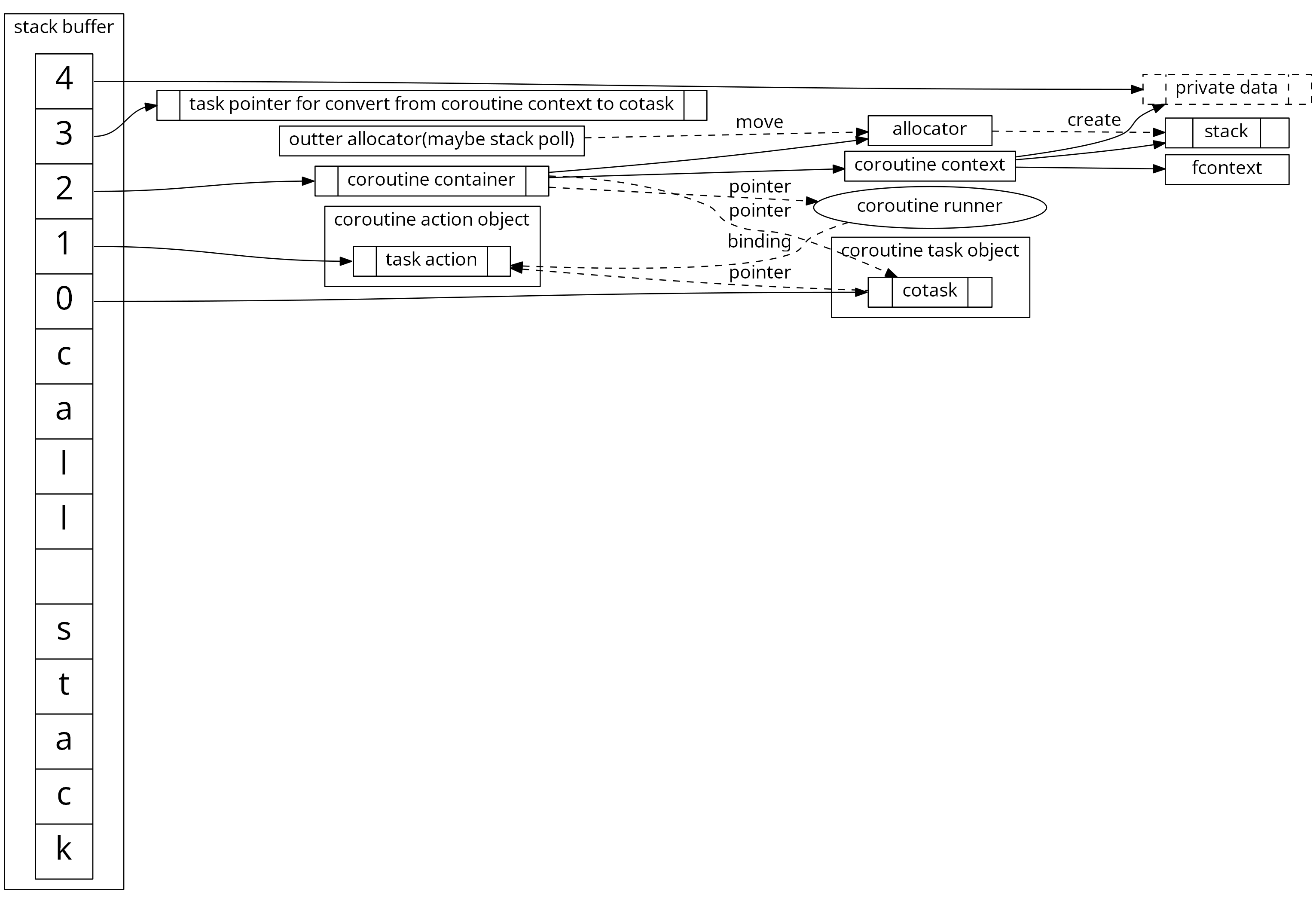
v2版本在这方面就有了一些优化。基本思路是每个协程执行的时候都必然会分配一个执行栈,那么其实我们在执行栈上开辟一块空间放这些对象(执行栈是自顶向下增长,所以可以放到栈空间的最后面)。同时还可以开辟出一块用户私有数据块,用于方便使用者可以存放一些 TrivialType 的私有数据,也不需要额外的动态分配。当然,各项组件的可自由组装和裁剪的特性也是必须保留的,我们的组织结构如下图所示:
栈池
在压力测试过程中,我们发现其实相对于业务逻辑,协程的创建和切换的开销占比非常小。但是有一样的开销很高,那就是缺页中断。我们知道在Linux中,在内存地址被实际使用前,是不会有物理内存页映射进来的。在第一次访问未映射地址的时候(特别是协程第一次切入到执行栈),会触发一次缺页中断,然后由操作系统把实际物理页映射上去,然后再继续执行。这个缺页中断引起的开销是其他协程创建流程总和的大约10倍左右。所以为了减缓这种开销,我们引入了一个新的stack allocator - 栈池allocator。目前栈池的实现是一个比较简单的但基本可用版本,并且初步实现了可以根据负载自动调整池子大小的功能。这样在低负载服务中可以有效减少内存消耗,在高负载服务中也能提高复用率。
性能对比
从压测结果上看,v2版本对v1的CPU L1缓存命中率是有下降的。我们分析这是因为v1版本中对象是碎片化的关系。因为碎片化的对象底层有 jemalloc 的加持,导致即便是在手动构造的栈cache miss的压力测试中,由于我们压测的CPU的L1 cache是32KB=8way*64sets*64B的,导致访问前一个对象的时候,后一个对象还是有部分数据被加载到了缓存中,小对象的缓存命中率还是比较高。这其实也是不符合实际应用场景的。
因为一般情况下我们并不是为了跑分而优化,协程接口一般在切换上下文后逻辑会更加复杂。所以为了尽可能贴近实际应用,我们尽量构造cache miss的用例来评估性能。同时我们大部分项目上线的时候编译选项都是-O2,所以在压力测试的时候我们也尽量使用O2级别的编译优化(有些系统自带包会用O3),编译选项是 -O2 -g -DNDEBUG -ggdb -Wall -Werror -fPIC 。项目中一般会启用安全性较高的方案,所以我们的压力测试中,只要是可以定义栈分配的库,栈都使用mmap出来4K对齐的页和使用mprotect尾部的方式来维护栈空间。
压力测试机环境
| 环境名称 | 值 |
|---|---|
| 系统 | Linux kernel 3.10.104(Docker) |
| CPU | E5-2630 v2 @ 2.60GHz * 12 |
| L1 Cache | 64Bytes*64sets*8ways=32KB |
| 系统负载 | 1.27 1.29 1.17 |
| 内存占用 | 2.86GB(used)/2.84GB(cached)/2GB(free) |
| CMake | 3.11.3 |
| GCC版本 | 8.1.0 |
| Golang版本 | 1.10.2 (20180216) |
| Boost版本(libgo依赖) | 1.67.0 |
| libco版本 | 0af0b89998f2f691208f530cacb799ed033098f6 (20180605) |
| libcopp | 8ce6dfef26ccf6a1ecb55336dde18a6526f76666 (20170423) |
压力测试对比
| 组件(Avg) | 协程数:1 切换开销 | 协程数:1000 创建开销 | 协程数:1000 切换开销 | 协程数:30000 创建开销 | 协程数:30000 切换开销 |
|---|---|---|---|---|---|
| 栈大小(如果可指定) | 16 KB | 2 MB | 2 MB | 64 KB | 64 KB |
| libcopp | 60 ns | 3.7 us | 91 ns | 3.5 us | 239 ns |
| libcopp+动态栈池 | 60 ns | 109 ns | 90 ns | 261 ns | 238 ns |
| libcopp+libcotask | 79 ns | 4.2 us | 124 ns | 3.8 us | 338 ns |
| libcopp+libcotask+动态栈池 | 80 ns | 246 ns | 126 ns | 340 ns | 335 ns |
| libco+静态栈池 | 94 ns | 7.1 us | 180 ns | 5.7 us | 451 ns |
| libco(共享栈4K占用) | 94 ns | 3.8 us | 173 ns | 4.0 us | 558 ns |
| libco(共享栈8K占用) | 95 ns | 3.8 us | 1021 ns | 3.8 us | 1810 ns |
| libco(共享栈32K占用) | - | 3.8 us | 6275 ns | 4.0 us | 6429 ns |
| libgo with boost | 197 ns | 5.3 us | 124 ns | 2.3 us | 441 ns |
| libgo with ucontext | 539 ns | 7.0 us | 482 ns | 2.7 us | 921 ns |
| goroutine(golang) | 464 ns | 578 ns | 538 ns | 1.4 us | 799 ns |
| linux ucontext | 356 ns | 4.0 us | 431 ns | 4.5 us | 946 ns |
libcopp+libcotask比单纯的libcopp多了进程内唯一ID的分配、状态转换和维护、可调用对象和跳转函数直接的转换和事件响应,并且保证了线程安全。工程上一般会用libcotask,但是功能上libcopp才是和其他对比项类似的部分。在压力测试中,也没有包含libco和libgo里系统函数hook的部分。
libgo的作者已经不再建议使用共享栈所以我们没有压测libgo的共享栈性能。libgo采用锁实现了线程安全,我们压测过程中没有启动多线程所以测试结果也不包含线程等待的消耗。
libco仅支持静态栈池,并且静态栈池只是为了减少共享栈时的copy开销,所以libco也分别对模拟栈使用量为4K、8K和32K时模拟栈池耗尽时的压力测试,可以看到栈使用量较大时,切换的memcpy开销较大。但是在工程中,libco的栈池也不会只分配一个,所以项目中的真实消耗还是要看最终的命中率,如果栈池剩余量越大,性能更向第一组靠近,否则根据栈使用量向后面靠近。
- libcopp/libcotask测试代码:https://github.com/owent/libcopp/tree/v2/sample
- goroutine 测试代码: https://gist.github.com/owent/1842b56ac1edd5a7db54590d41af1c44#file-goroutine_benchmark-go
- libco 测试代码: https://gist.github.com/owent/1842b56ac1edd5a7db54590d41af1c44#file-libco_benchmark-cpp
- ucontext 测试代码: https://gist.github.com/owent/1842b56ac1edd5a7db54590d41af1c44#file-ucontext_benchmark-cpp
- libgo 测试代码: https://gist.github.com/owent/1842b56ac1edd5a7db54590d41af1c44#file-libgo_benchmark-cpp
【协程数:1,栈大小16KB】 - 切换耗时对比
【协程数:1000,栈大小2MB】 - 创建耗时对比
【协程数:1000,栈大小2MB】 - 切换耗时对比
【协程数:30000,栈大小64KB】 - 创建耗时对比
【协程数:30000,栈大小64KB】 - 切换耗时对比
总体来说,libcopp和libcotask还是很有优势的。特别是动态栈池,几乎可以让创建开销逼近上下文切换,可以放心地无脑创建协程了。这里面需要特别说明一下的是goroutine和libco。goroutine的切换并没有优势,但是创建性能还是挺高的,原因之一是我对go不是很熟,不太清楚怎么让go的cachemiss掉,看起来它自带一些池子的功能。而libco是支持静态栈池的,如果静态的栈池足够大或者使用量不大的时候,也能有不错的切换性能(不需要memcpy栈),只是池子用完以后波动会很大。