前言
年前就计划把以前项目的一些理念和设计方案融合到sample里来。但是内容比较多,一直也没太多时间去完成它。所幸虽然断断续续但终归是完成了。并且在之前的一些实现上还做了一些细节的优化。内容比较多我感觉我自己写的也比较乱,仅当作一个参照和小计吧。
协程系统优化
本来想直接写这里,但是写着写着有点长,就专门开了一篇,顺便补了和同类库的性能对比。详见: https://owent.net/2018/1806.html
对象路由
之前给我的上一个项目设计了对象路由系统,但是直到最近才有时间整理抽象并优化一下合入到 框架sample 里来。 原来的路由系统的设计见 https://owent.net/2017/1342.html 。
设计对象路由系统的主要目的:其一是统一游戏中不同类型的对象的续期、降级/升级、自动保活、定时保存的功能,这样不需要每种类型都单独实现一遍。当然因为游戏对象的种类非常多,要适应性足够好,就不得不加一些约定,暴露比较多的接口,也导致接入的复杂度稍微高一些;其二是统一转发消息给某个对象时,能够自动发送到对象负载均衡或是容灾、扩容、缩容后所在的节点,并且统一这个流程。
一般像数据库都是行级sharding或者行+部分列sharding的,类型和业务比较单一,而游戏对象就比较复杂。比如公会服务,可加入、可退出、可踢出、可管理还有很多其他游戏业务的逻辑。而且每种不同类型的游戏需要分片的对象差异都很大。在以前的一些解决方案中,有按Hash去静态路由到某些服务节点上,如果这个节点挂了会导致分到这个节点上的对象的服务都暂时不可用。而且扩容或者缩容的时候,需要暂停服务,不然数据迁移过程中可能会在新节点拿到迁移数据前收到服务请求,又或是在老节点已经移交对象数据出去后又收到该对象的服务请求。而使用路由系统就不存在这样的问题,如果某个节点出现故障一段容忍时间后可以自动迁移到可用节点进行服务,而后这个对象的所有服务消息会被转发到新的节点上。扩容和缩容的时候也可以不停服,只要数据转移完了,所有消息都会被转发到新节点上。整体结构的设计思路有点像Redis Cluster(详见: https://redis.io/topics/cluster-spec )的结构,但是实现和流程细节有一些差异。
之前介绍过这个对象路由系统的设计了,这里就不重复了,着重说一下在之前的设计上进一步的优化。
优化一: IO排队自动化
第一个优化是IO自动排队。所谓IO就是读取和保存的任务。在之前的设计中,如果缓存不存在的时候同时来多个消息,则会拉取多次。虽然多次取回后会丢弃冗余的数据,逻辑上不会有问题,但是还是不必要地发起了拉取请求。
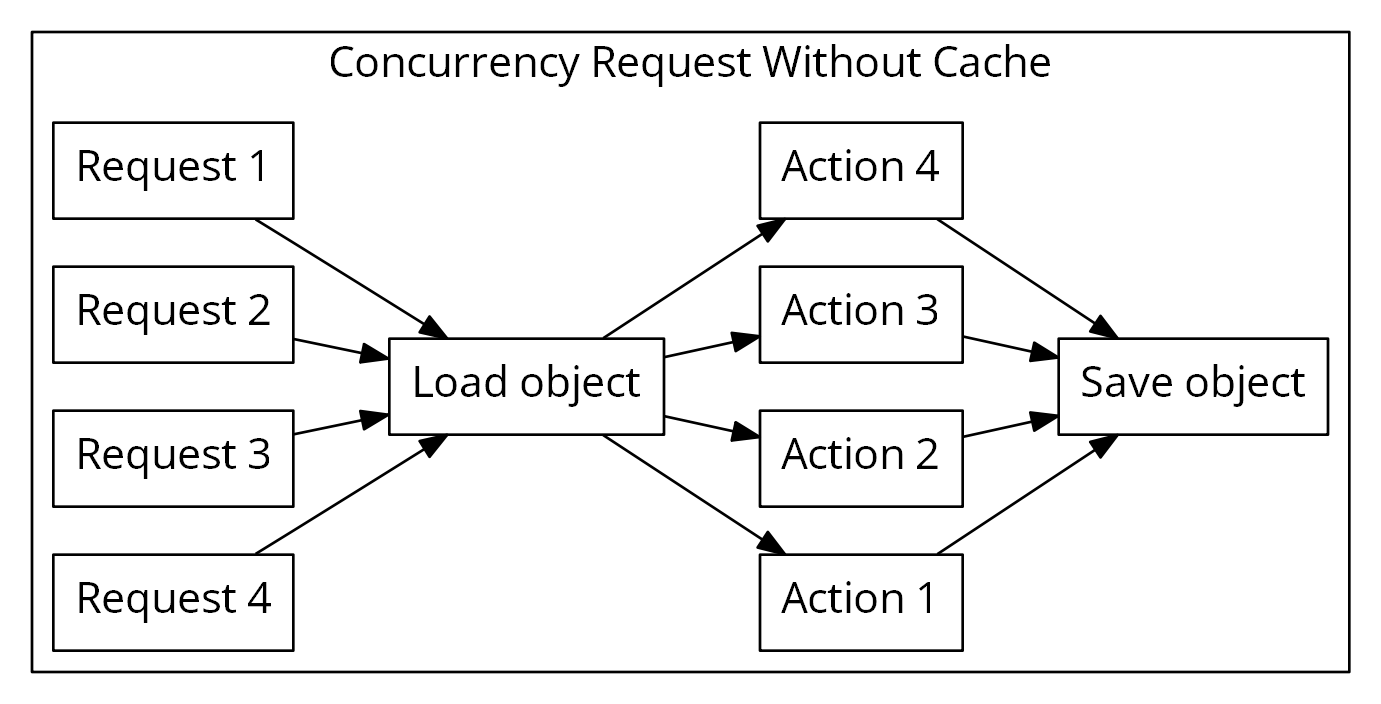
当然,如果路由缓存本身就存在,就也不需要拉取,直接回并行执行所有的任务。
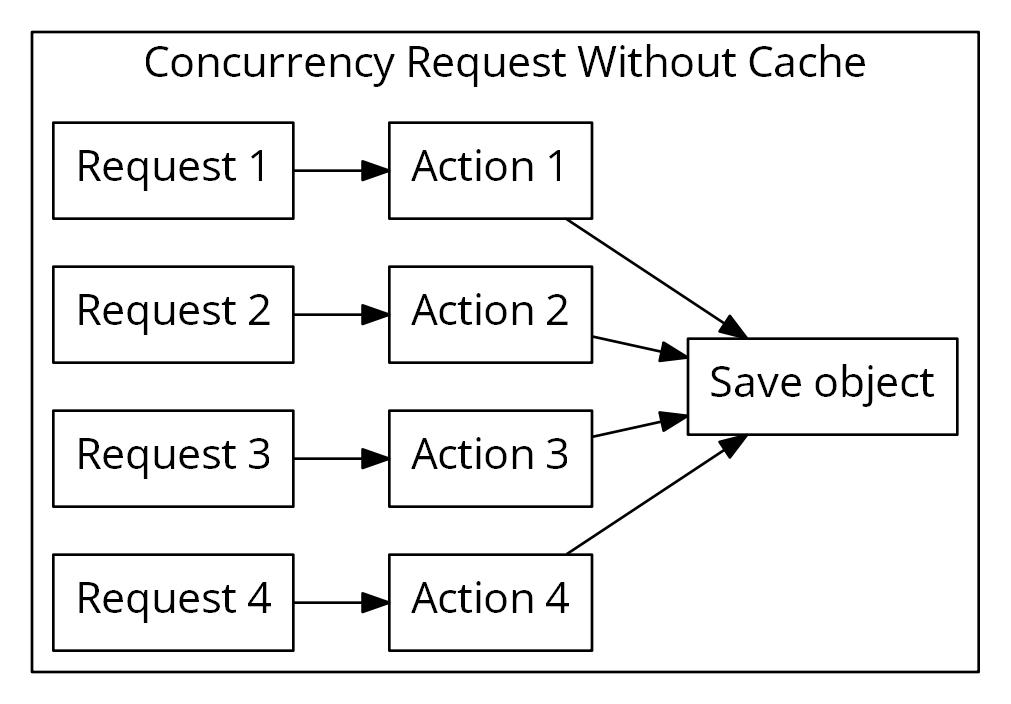
同时在保存地时候的次序也是依赖了数据库层的顺序。而这里的IO自动排队就是解决这个问题,在拉取和保存的时候收敛到一处,并且还可以自动合并保存版本。
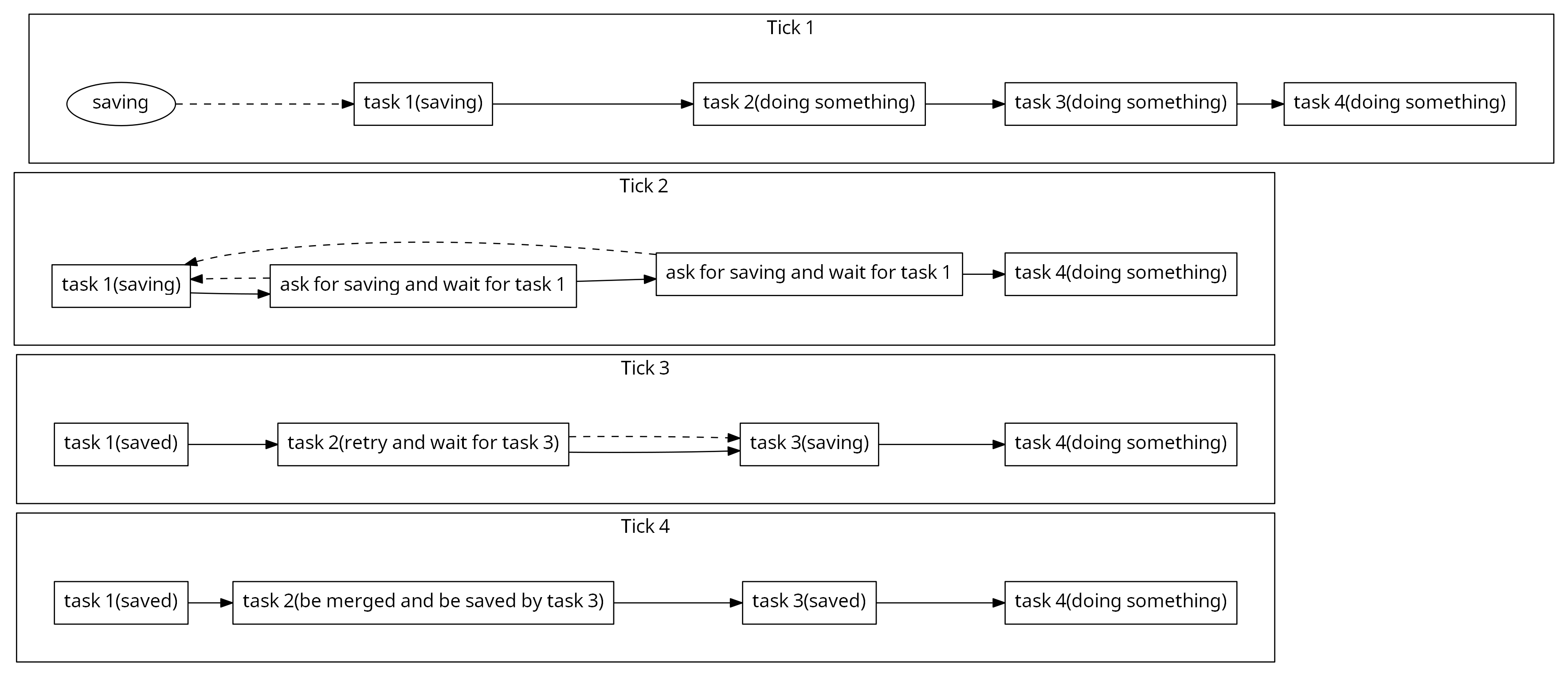
比如上面所示的流程里,针对于某个对象,Task 2和Task 3在准备保存的时候Task 1在执行保存任务,那么Task 2和Task 3会等Task 1返回后再次执行保存。这时候因为Task 2和Task 3的数据都已经更新了,所以只需要保存一次最新的数据到数据库,就同时保证了Task 2和Task 3的保存都成功完成。这种情况下就产生了一次数据的Merge并且减少了一次保存开销。
IO排队后的另一个优势是能很容易地保证和事件的时序。试想假设我们第一个协程执行踢出,第二个协程又执行读入。这时候首先第二个协程会等待第一个协程完成,然后第一个协程内会触发Remove事件,而后第一个协程完成,第二个协程Resume并触发Load事件。这很自然地保证了我们地事件触发流程跟着API调用走。而在从前,要保证这种情况下严格的逻辑时序,要么只能让对一个对象的操作串行化,要么需要编写额外的代码来标记状态。
协程里执行IO还有一个优势就是可以很容易地实现FlagGuard:
int router_object_base::pull_cache_inner(void *priv_data) {
// 触发拉取缓存时要取消移除缓存的计划任务
unset_flag(flag_t::EN_ROFT_SCHED_REMOVE_CACHE);
task_manager::task_ptr_t self_task(task_manager::task_t::this_task());
if (!self_task) {
return hello::err::EN_SYS_RPC_NO_TASK;
}
int ret = await_io_task(self_task);
if (ret < 0) {
return ret;
}
// 先等待之前的任务完成再设置flag
flag_guard fg(*this, flag_t::EN_ROFT_PULLING_CACHE);
// 执行读任务
io_task_.swap(self_task);
ret = pull_cache(priv_data);
io_task_.reset();
if (ret < 0) {
return ret;
}
// 拉取成功要refresh_save_time
refresh_save_time();
return ret;
}比如这段代码的 flag_guard fg(*this, flag_t::EN_ROFT_PULLING_CACHE); ,我们就可以很方便地用RAII的方式来设置flag。在 ret = pull_cache(priv_data); 会协程切出,而这个异步流程完成前 flag_guard 都是有效的。
优化二: 快队列
我们在路由系统设计了一个全局定时器管理器,统一管理对象的超时降级、定时保存和缓存淘汰问题。但是当定时器触发的时候可能这个对象正处于某种操作中,比如正在执行IO操作而不能立刻降级或者移除,这时候我们回尝试重新将其插入到下一轮定时器中。但是原先只有一种定时器,也就是下一次定时器操作可能是几分钟以后了。所以这里我又加了一个块队列,这种情况下只要等待很短的时间后就可以重试了。这样可以加快出现冲突时的资源回收。
设计细节优化
洽谈一些细节优化比较零碎了,我就简单记录一下吧。
调度系统优化
首先是消息不再需要全局container。原先协程消息必须全部包在一个叫 message_container 的结构体内,便于不同类型的 dispatcher 之间交互统一同一种message类型。这总归有一定的耦合性,每次增加 dispatcher 还得去加这个 dispatcher 的消息类型进这个公共的 message_container 。现在我抽象了一个 dispatcher_msg_raw_t 来描述消息类型。
struct dispatcher_msg_raw_t {
uintptr_t msg_type; // 建议对所有的消息体类型分配一个ID,用以检查回调类型转换。推荐是使用dispatcher单例的地址。
void *msg_addr;
};然后 msg_type 跟着 dispatcher 走,因为通常每一种 dispatcher 处理的消息类型是确定的,比如 ss_dispatcher 只处理服务器间消息 ss_msg , 而 cs_dispatcher 只处理客户端传上来的消息 cs_msg 。
统一异步指令流程
另外也是给协程的start和resume流程增加了 dispatcher_start_data_t 和 dispatcher_resume_data_t 。
struct dispatcher_resume_data_t {
dispatcher_msg_raw_t message; // 异步回调中用于透传消息体
void *private_data; // 异步回调中用于透传额外的私有数据
};
struct dispatcher_start_data_t {
dispatcher_msg_raw_t message; // 启动回调中用于透传消息体
void *private_data; // 启动回调中用于透传额外的私有数据
};这也是用于能够在派发消息的时候能够对类型做一次检查和利用编译器帮助执行一些API调用规范上的检查。这些检查以前都依赖于 message_container 里的描述反射。
etcd接入抽象层
我对 etcd 的接入也做了一层抽象,现在能更容易地利用现有组件搭建对etcd服务灵活地建立watch、keepalive。实现服务保活和监控,然后atproxy的服务发现、负载均衡和容灾也使用了这个新的套件。 还有一个简单的使用的例子在 https://github.com/atframework/atsf4g-co/blob/sample_solution/src/tools/etcd-watcher/main.cpp 。
整个组件分未三部分 etcd_cluster 、 etcd_keepalive 和 etcd_watcher 。 其中 etcd_cluster 用于维护 etcd 集群,它会定期向 etcd 集群拉取节点信息(因为可能对 etcd 调整部署和扩缩容),并且支持自动更新列表和fallback到配置的服务节点列表。 而 etcd_keepalive 和 etcd_watcher 都必须挂接在 etcd_cluster 里。
启用 etcd_keepalive 的时候会自动打开 etcd_cluster 的租约功能(lease)。当租约功能启用的时候,etcd_cluster 对向 etcd 集群申请一个租约,并且自动续期。然后所有的 etcd_keepalive 的key都会挂载在这个租约下。如果服务崩溃了会导致租约过期,而后被其他 etcd_watcher 的节点感知到。并且现在我们使用了 etcd 的v3版 API,不再单独续期key的TTL,只需要续期 lease 即可。这种情况下也不会触发key的变更事件。当然第一次启动的防冲突检查和主动的数据变更也是支持的,前者使用了回调函数来实现,并且提供了一个严格比较内存数据的默认实现。
etcd_watcher 顾名思义就是对某个路径做watch,用于感知集群里其他节点的变更情况。同样现在我们使用了 etcd 的v3版的流式请求,任何的网络错误都会定时发起带版本号的重试流程。
详情可见: https://owent.net/2018/1802.html
hostname判定优化
原先的配置生成脚本里的hostname用的是真的hostname 。不使用网卡MAC地址主要是考虑有些虚拟机可能没有配置网卡,或者多个网卡,或者网卡发生变化。但是实际使用过程中发现很多时候运维给的虚拟机都是一套模板出来的,很容易没改hostname,这样不同机器认为自己的hostname都一样了。所以这里调整了策略,还是回归成了取字典序后的网卡的MAC地址。如果没有网卡则可以随机一个UUID,因为这时候反正也访问不了外网节点。
simulator的优化和配置的时间单位
对于客户端模拟器 simulator 。我们新增了一个命令定时器,并且增加了一个内置命令( sleep ),可以延迟一段时间执行命令队列的后续指令。这主要是方便我做长时间多用户在线的稳定性和压力测试。
同时配置和命令系统增加了时间单位的支持,这样我们可以配置和执行类似下面这种命令:
sleep 100ms # 休眠100毫秒
sleep 10m # 休眠10分钟
sleep 1h # 休眠1小时后记
目前的一大波功能Merge和细节优化就这么多。后面可能还会有陆陆续续的小细节优化,量不大的可能就不写blog了。现在的 atsf4g-co 应该算是一个很完整并且很多技术细节和设计理念都比较先进同时性能也是属于一线水平的开源游戏服务器解决方案了。