前段时间有同事联系我想看看可能推广我之前写的协程库 libcopp,虽然 libcopp 已经用到过好几个项目上,这几年也断断续续地写了一些实现细节的文章,但是也但确实需要系统、概览性地介绍下 libcopp ,所以就有了这篇文章。
Github: https://github.com/owent/libcopp Document: https://libcopp.atframe.work/
libcopp 的由来
协程的概念并不是什么非常新颖的东西,最早有做 libcopp 的想法的时候,是听了微信分享的 libco 。但是我们游戏业务里大部分的实现都还是走的事务和Task/Step的模型,特别是C++上异步调用非常不直观。而这种协程的方法可以比较容易地把接口设计得很简洁,而且后续的功能集成上也很容易不破坏原有的API约定,还有微信这么大的业务背书,我们就想在游戏业务里也使用这种方案。我们先是预研了一些类似的方案,但是都不是特别满意。
相似方案
首先是 libco。 libco 其实文档比较少,有些使用方式要看它的代码,而且是只支持Linux,但是对编译器的要求还不太明确,而我们项目组有时候会用一些比较新的东西,也是怕后面兼容性上不一定能保证。libco 一大特色是它的共享栈功能和对IO API的hook。前者的设计模式其实我是不太赞同的,因为它会留下一些坑(比如不能传出栈上变量到外部使用),而且对性能影响很大;后者其实对我们的用处不大,因为我们很少会直接去使用那些底层API,而是会接入很多库或者其他接入层来使用,更需要的是容易自定义。另外 libco 开源出来的仓库似乎几乎没有测试,只有一些sample,总给人一种不太放心的感觉。
我们还研究了 boost.context ,现在 boost 又有了新的 boost.coroutine 和 boost.coroutin2 库,但是当时还没有。 boost 库的兼容性和测试都一流,而且整个编程风格都是C++的,性能足够高,看起来非常良好。但是当时 boost.context 只有很底层的接口,使用上并不是很方便,另外 boost.context 对上下文对象管理的部分其实适配上也有一些问题。比如当时我们测过一些环境里,编译器版本比较高,但是缺失STL的TLS实现,boost.context就会直接链接不过。另外 boost.context 最大的问题是它依赖整个 boost 的平台和环境检测代码,非常重(即便用 bcp 提取依赖,仍然非常重)。我们其实非常排斥为了引入一个小组件,而导入一个超大规模的框架的。而后来出现的 boost.coroutine 我认为实现架构上我觉得是有一些问题的,兼容性更差,实用性也不好,现在已经 deprecated 掉了, 再后来的 boost.coroutin2 我之前初步看了一下,感觉结构和 libcopp 的 copp 部分差不多。
在当时 libgo 当时也算是一个比较完善的协程框架了。它做了很多语法糖,上手很简单。当时它也做了和 libco 一样的共享栈功能,但是后来作者不建议使用了,不知道是不是和我们一样的想法。libgo 也是依赖的 boost.context, 但是当时它还没有打包一份出来自己维护,所以也算是依赖很重的框架。它的自定义接入层很简单,但是其实底层是绕了一圈,而且我们的业务需要自己控制调度层,而它提供的调度层我们似乎并不是很容易剥离,即便剥离了也会有一部分不必要的开销。
直接基于linux的swap_context和make_context的方案也是不是很完整,还是需要自己封装而且性能不太令人满意。其他的方案其实大同小异,我们就没有逐个去看了,最终还是选择了自己实现一个。于是 libcopp 就诞生了。
设计目标
我设计 libcopp 的时候优先还是考虑到我涉及的业务类型(游戏服务器)的。 首先我当时的想法是,既然用协程,就是为了简化业务开发人员的心智负担,并且能够容易排查问题,而且非共享栈带来的问题可以通过其他手段消除掉,所以没有去实现共享栈的功能(其实早期是预留了实现共享栈的空间的,后来觉得没必要去掉了)。
在游戏业务服务器里,会有需要接入各种各样的SDK和调度方式,所以容易集成其他系统就成了最大的优先级。
跨平台的特性是为了我们当时不同人都有自己的开发喜好,每个人都有自己喜欢的工具、环境和流程,我希望是能够适配大家的环境,提供可用且功能一致的版本,在这个基础上,我们线上业务是运行在Linux上的,所以Linux上性能最大化也是优先考虑的。
在设计 libcopp 的时候,我也是尽量按照C++的设计风格。因为我觉得现代C++的很多工具对我们排除一些初级错误很有帮助(比如 static_assert ),所以在实现 libcopp 的过程中,我们是会检测环境并且尽可能地使用 C++ 的一些新特性来优化性能或是规避问题;另外,因为整体架构和一些编程方法是可能随着时间而演进的,所以我们设计 libcopp 还会尽可能地让其内部的组件,是可单独拆卸下来的,并且容易剥离和重组,这点一定程度上参考了 boost.context 的设计;同时我们也会注重单元测试,保持比较高的覆盖率,这样对以后的修改能够更放心一些。
所以下面就是我们总结的设计目标了:
- 跨平台(Linux/macOS/Windows/MinGW + GCC/Clang/MSVC)
- 高性能
- 易集成,不容易误用,线程安全
- 功能简洁,正交性
- 容易定制化
- 依赖少
- Modern C++
上面的目标其实也不只是游戏服务器业务的需求点,而是想要保持足够灵活。这样如果其他业务要使用,只需要做少量的接入工作即可。
下面是一些常用方案的简单对比(可能理解上会有差错请见谅):
| 协程库/方案 | 跨平台 | 原生线程安全支持 | 外部依赖 | 创建性能 | 切换性能 | 扩展性 | 原生IO支持 | 设计模式 |
|---|---|---|---|---|---|---|---|---|
| libcopp/libcotask | Windows/Linux/macOS等 | 所有接口支持 | 无 | 极好 | 很好 | 很好,易扩展,模块化设计 | 无 | C++,仿promise |
| boost.context | Windows/Linux/macOS等 | 否 | 很重,依赖boost | 不一定 | 很好 | 很好,原生功能简单 | 无 | C++,需要二次封装 |
| boost.coroutine2 | Windows/Linux/macOS等 | 否 | 很重,依赖boost | 很好 | 很好 | 很好,较复杂,模拟IO回调 | std/boost | C++,pull/push回调模型 |
| libgo | Windows/Linux/macOS等 | 部分,由内置调度层管理 | 很重,依赖boost | 一般 | 很好 | 较好,内置调度器,模拟channel | IO API Hook | 仿goroutine |
| libco | 仅支持x86/x86_64的Linux | 否 | 无 | 很好 | 不一定 | 一般,内置静态栈池 | IO API Hook | 无,需要二次封装 |
| linux ucontext | 仅支持Linux | 否 | 无 | 一般 | 一般 | 一般,只有上下文切换 | 无 | 无,需要二次封装 |
| call_in_stack | 仅支持x86/x86_64的Linux | 否 | 无 | 极好 | 极好 | 一般,只有上下文切换 | 无 | 无,需要二次封装 |
| librf | 目前仅支持Windows+MSVC | 部分,由内置调度层管理 | 依赖C++20 | 很好 | 极好 | 较好,内置调度器,模拟channel | ASIO | 仿goroutine,仿promise |
| C++20 Coroutine | Windows/Linux/macOS等 | 否 | 依赖C++20 | 极好 | 极好 | 很好,但非常复杂 | 部分STL | 无栈协程,需要二次封装 |
| goroutine | Windows/Linux/macOS等 | 否 | golang | 好 | 一般 | 很好,易扩展 | golang | channel |
基本原理和实现架构
libcopp 属于对称式有栈协程,有栈协程的基本原理很简单。不同平台,不同架构的架构下的 ABI 对函数调用都有一定的规范,比如 x86_64 的基本规范是要求函数的被调方保留好上一帧的 R12 、 R13 、 R14 、 R15 、 RBX 、 RBP (其他特殊的功能比如TSX或者Linux下GCC的动态栈还需要有其他的内容), 在函数返回后还原,然后函数栈的起始地址有对齐要求。 而有栈协程即是把这些要求被调方处理的寄存器内容保存在栈上,然后直接jmp到新的执行地址即可。在跳回来以后需要还原这些寄存器,对调用方来说,就像调用了一个函数一样。
我没有挨个平台去看 ABI 的文档,所以为了实现跨平台,我在 libcopp 里是直接引用了 boost.context 里的 fcontext 部分。但是我把它的平台判定和汇编层代码剥离出来并且重命名了符号,这样可以不依赖庞大的 boost 库,而且如果哪个项目要用 boost 也不会冲突。项目里的 BOOST_LICENSE_1_0.txt 也是这个原因而存在。
libcopp 大体上分为两部分.第一部分是 copp ,这部分主要负责偏底层的协程上下文管理、栈管理; 第二部分是 cotask , 这部分主要用于一些更高层面的设计模式和基于协程的任务模型(包括但不限于进程内 唯一ID分配 、 超时管理 、 await语义 、 自定义参数 的关联和分配等等),还包含一个 task_manager 用于基于ID的统一管理和提供超时管理。
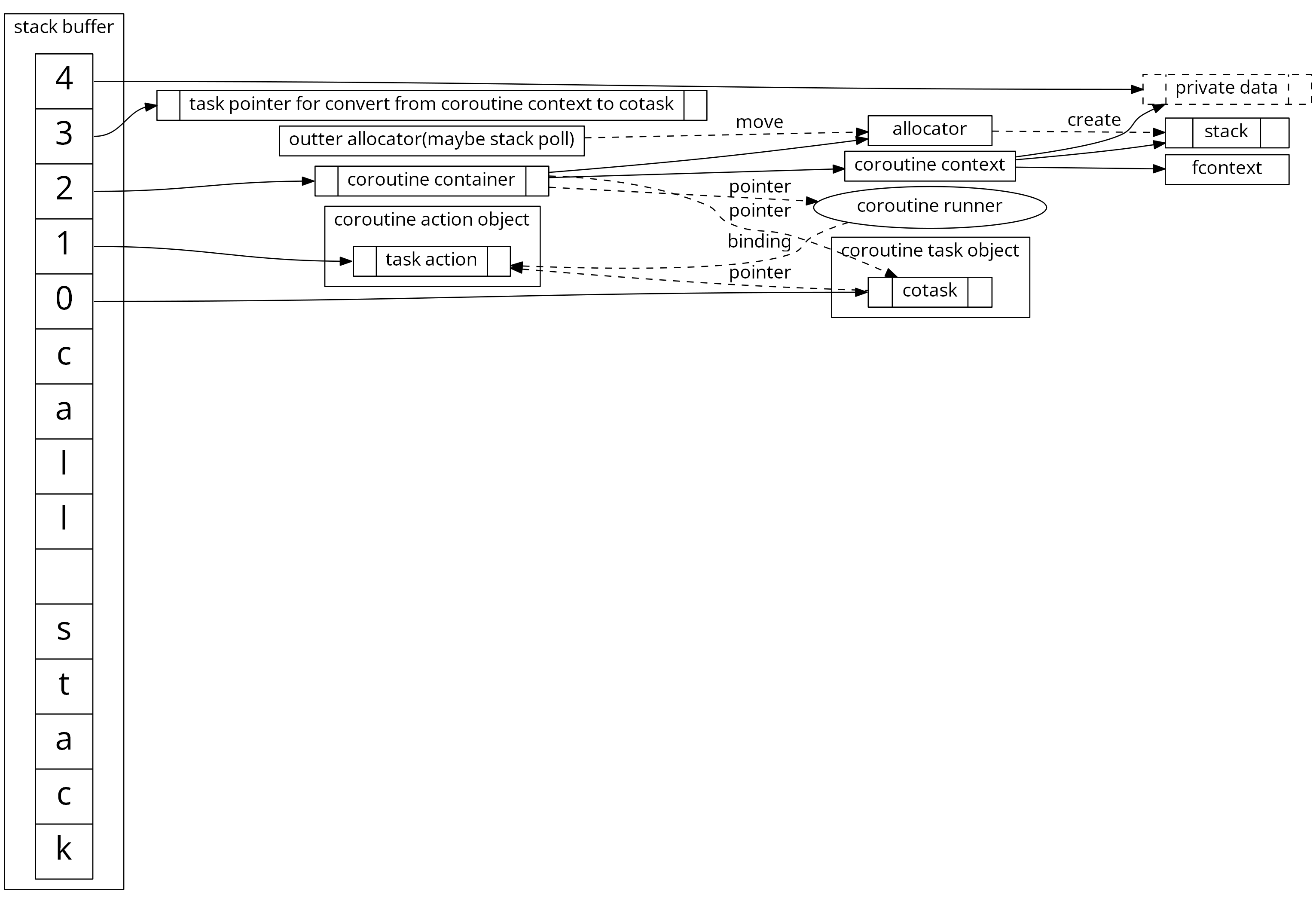
其中 copp 里还分为 栈分配器 、 执行上下文管理 和 用户自定义数据 , 其中 栈分配器 是可自定义的,只需要类似 std::allocator 实现几个接口即可,我们也提供了几个内置的分配器供直接使用,包括 通过malloc分配 、 mmap/unmap(Windows下是VirtualAlloc/VirtualFree) 、 自定义指定内存地址的分配器 、 Linux下的动态增长栈分配器 和 动态栈池分配器 。这里面 动态栈池分配器 还支持搭配底层使用上面其他的分配器。cotask 是可选的,如果业务有自己的任务系统也可以不用,并且可以通过编译选项完全关闭, 而在 cotask 里,ID分配器 也是可以自定义的。 这样所使用的业务可以根据自己的需要来选择、搭配或是自定义用自己项目里统一的管理系统。
关于栈池分配器
栈池分配器起源于我大规模使用 libcopp 的一个项目压力测试的时候,发现实际的CPU占用和预期相差比较大(当时预期 libcopp 的开销时1%左右,但是实际大约 10%)。 后来分析出来大部分的开销耗在了 缺页中断 上面。libgo 和 boost.coroutine2 也有这个问题,而 libco 分配的栈一般都是malloc出来的而且会复用不太会出现这种情况。 其实在 libcopp 里如果选择使用 通过malloc分配 或者 自定义指定内存地址的分配器 也不会有这个问题。但是我们希望项目中发现问题(特别是栈溢出)为第一优先级,所以通常我们都会选用 mmap/unmap(Windows下是VirtualAlloc/VirtualFree) 。这时候这个问题就凸显出来了,因为每次分配的时候都重新建立地址映射,那么物理页肯定就被释放了。 为了解决这个问题,我们就写了一个 动态栈池分配器 。这个分配器基本不需要设置,接入也只需要简单地改两处调用的代码即可。而之所以是 动态 的是因为我们项目中一台机器上可能会搭建很多测试环境,这些环境往往都是低负载、版本不同且提供给很多不同的人用的,所以可以减少低负载服务的内存占用,并且尽可能多地利用好已有 内存映射的逻辑地址 。 所以最终 动态栈池分配器 提供的功能是:
- 栈对象采用 FILO 的模式
- 高负载会自动提高栈池容量,并且带有数量和地址空间大小上限
- 低负载会自动减小容量,并且带有数量和地址空间大小下限
- 可以控制每个tick的回收数量,防止长时间 Stop The World
v1 -> v2的架构变化
libcopp 有一次比较大规模的重构,其实是伴随着 boost.context 1.61 版本的一次底层结构大重构。(关于这次 boost.context 的变化的细节可以参见《boost.context-1.61版本的设计模型变化》)。这次 boost.context 的大重构把它的底层 由对称式协程上下文改成了非对称式 ,并且接口上对参数透传更加友好。这其实增大了底层上下文使用者的很大的灵活性。但是 libcopp 在应用中还是使用的对称式 ,而且对称式理解和管理起来更方便,所以 libcopp 还是还原了对称式的做法。另外新模型的 boost.context 的还增加了一个 ontop 事件,用于便于在切入前做一些事情。但是 libcopp 有自己的事件管理,并且还没发现实用的场景,所以还没有使用这个功能。
boost.context 其他的变更可以参见 《libcopp的线程安全、栈池和merge boost.context 1.64.0》
随着这次的结构大重构,我就给 libcopp 做了一些其他优化。大致的内容是使用分配的栈空间来存放 libcopp 自身所需的数据结构,并且留了接口给使用者指定自定义的私有数据块。copp+cotask的数据结构对齐以后占用空间大约 是192字节 ,但是由于栈空间都是对齐到4K的,所以 libcopp 内部对象都会落在CPU Cache的同一组 Cache Line上,导致压力测试的场景下命中率有所下降。另外还使用自己实现的侵入式智能指针代替原有使用的 std::shared_ptr ,这个的目的是简化接口并且在不需要多线程的时候提供给用户选项关闭多线程安全,这样可以减小智能指针和内部为了保证线程安全的原子操作导致的CPU Cache强制失效。
这一次的重构的更多细节可以参见 《libcopp v2的第一波优化完成》 。
后来还有一些优化是针对CPU代码缓存命中率的优化和对对齐的优化,这些对实际应用中影响比较小(主要是实际业务中使用不会是压力测试的时候那么“纯净”的环境)所以没有单独写文章记录。在开发 libcopp 的过程中的一些比较重要的节点和当时的思考都在 https://cn.bing.com/search?q1=site%3aowent.net&q=libcopp 了。
性能对比
有栈协程比起无栈协程的一个劣势是有代码段和数据段的跳转,不利于编译器的分析和优化和系统缓存的命中,所以性能上肯定是比不上无栈协程(比如 C++20 Coroutine )。但是有栈协程比无栈协程也有一个非常大的优势在于对API设计完全没有要求,框架开发者可以做到对上层业务完全透明。在有栈协程中 libcopp 不说性能最好,也算是第一梯队的了。之前我做过一个协程的性能对比,也包含了 C++20 Coroutine 的无栈协程。
更细节的详情可以参见: 《C++20 Coroutine 性能测试 (附带和libcopp/libco/libgo/goroutine/linux ucontext对比)》 和 《协程框架(libcopp)v2优化、自适应栈池和同类库的Benchmark对比》
工具集成
libcopp 在设计之初也是希望使用的时候能够简单方便,所以对一些流行的工具做了支持。
CMake Module
libcopp 本身是使用 cmake 管理的,所以理所当然会提供对 cmake 的 find_package 的支持。最早 libcopp 是提供了一个 FindLibcopp.cmake 文件以供使用。但是后来 cmake 3.0 开始推荐使用新的 Module 模型,通过提供 XXXConfig.cmake/XXX-config.cmake 和 XXXConfigVersion.cmake/XXX-config-version.cmake 所以现在的 install 流程也会安装用于支持 find_package(Libcopp) 的配置文件。
其他的发布环境下使用还是需要使用原始的 install 完后指定include和lib目录的形式。
vcpkg
vcpkg 是 Microsoft 开发的一个C++的跨平台包管理工具,整个系统也是基于 cmake 的,很容易就可以支持了。现在已经可以通过 vcpkg 的 vcpkg install libcopp 来安装 libcopp。
单元测试和压力测试
libcopp 里使用的是一个自己实现的轻量级单元测试框架,这样可以提供基本的测试功能并减少依赖。这个简易的单元测试框架也提供了编译开关来切换到 boost.test 或者 gtest 。然后在CI工具里集成了单元测试和压力测试以便观测一些修改对性能和API接口的影响。
文档
目前 libcopp 的文档不算特别好。现在是通过 doxygen 和 pacman 自动生成的API文档并发布在 https://libcopp.atframe.work/ 。README里和sample里目前仅有一些典型的使用方法,反倒是单元测试代码里有所有的接口。现在对一些稍微复杂的使用可能还是需要用户看单元测试来做参照。
后续规划
C++20 Coroutine 已经正式进入了草案,并且它在运行性能、内存占用、语法糖上都有绝对的优势。虽然说离能够正式使用还很遥远,但是底层的库的适配都需要先行。libcopp 的下一步计划是思考如何能够和 C++20 Coroutine 搭配起来,甚至后面如果往 C++20 Coroutine 上迁移能够平滑地进行。其实要实现让 libcopp 支持C++20 Coroutine 的 co_await 并不是很困难,稍微麻烦的地方在于如何判定编译器和环境是否支持。而另一个最大的困难在于像如何使用或者过渡到 C++20 Coroutine 的上下文模型。C++20 Coroutine的一大问题是接入非常麻烦且几个模块的关系非常不直观,如果哪天正式项目中可以使用了肯定是包了好几层的。那么对于 libcopp 来说就是以后对 C++20 Coroutine 如何封装和如果能够较容易地过渡过去。
另外就是一些其他环境兼容性检测,和周边工具的支持比如 cpack 和迁移CI到 Github Action 。
开源和交流
libcopp 刚开始的时候就是开源的,当时并没有什么特别的想法,只是说这样存取代码和交流会更方便些。 开源出来以后有一些小伙伴们提出过一些很实用的意见和建议,我也根据实际使用场景针对性地做了各种优化,也算查漏补缺吧。也同时特别感谢下 mutouyun 和 yuanzhubi 都对一些实现细节提供了很多很有用的建议,也欢迎其他有兴趣的小伙伴们一起提意见和交流哈。